本文主要分析
ping命令的函数调用情况和不同场景下的区别
1. 环境及过程
两个机器, Host A(5.5.5.11)和Host B(5.5.5.22), 物理网口(40G Mellanox CX4)直连. 在Host B上, 分三种情况
- ping对端:
ping 5.5.5.11, 即ping对端物理网卡的IP - ping自己:
ping 5.5.5.22 - ping localhost
ping localhost
然后考察函数调用的异同
2. 记录并解析函数调用
sudo perf record -g ping localhost, 留稍长的时间给perf来采样, 这里有一两分钟就够了.sudo perf script | ~/repo/FlameGraph/stackcollapse-perf.pl | ~/repo/FlameGraph/flamegraph.pl > ping-localhost.svg, 解析用到flamegraph工具, 需要到github上下载.
3. 流程分析
大致的过程是: ping先建立socket(sys_socket), 然后sys_sendto来发包, sys_recvmsg收包. 主要是内核协议栈在干活.
三个场景的火焰图见下:
3.1. ping peer
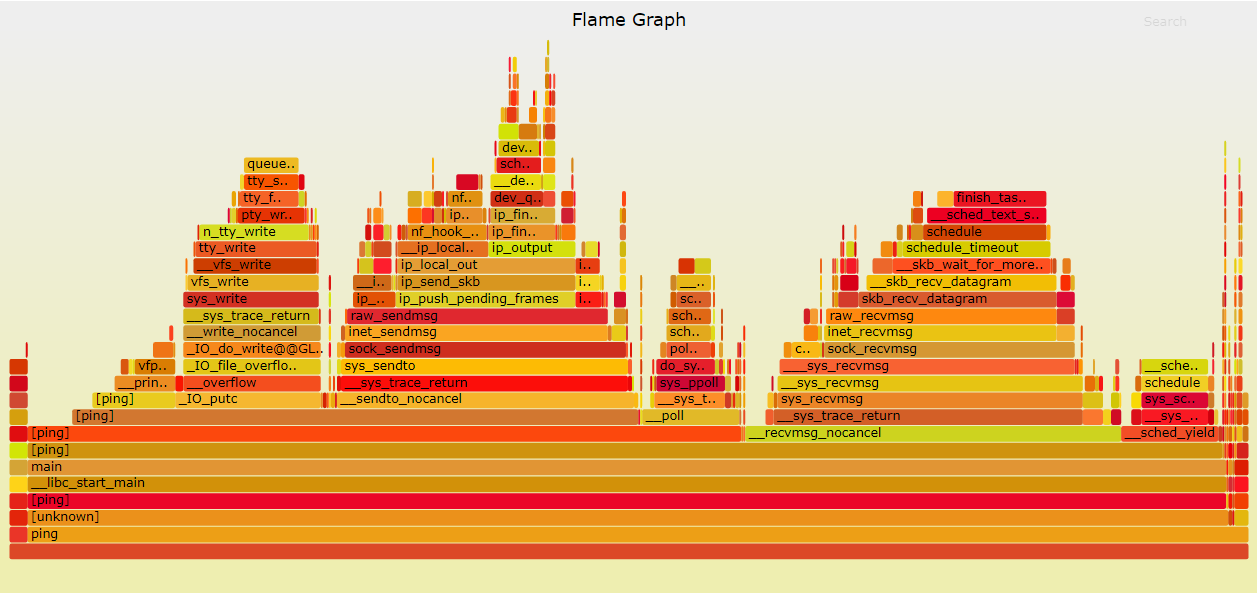
核心的发送路径如下: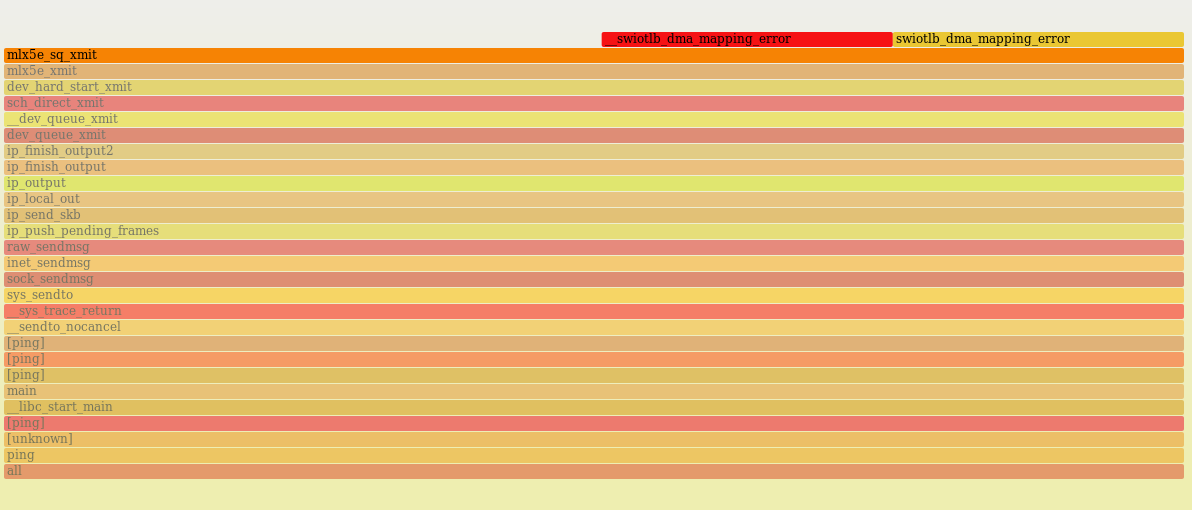
可以看到从系统调用sys_sendto开始, 到调用实际物理网卡mlx5e_sq_xmit发送报文结束.
流程如下:
3.2. ping self
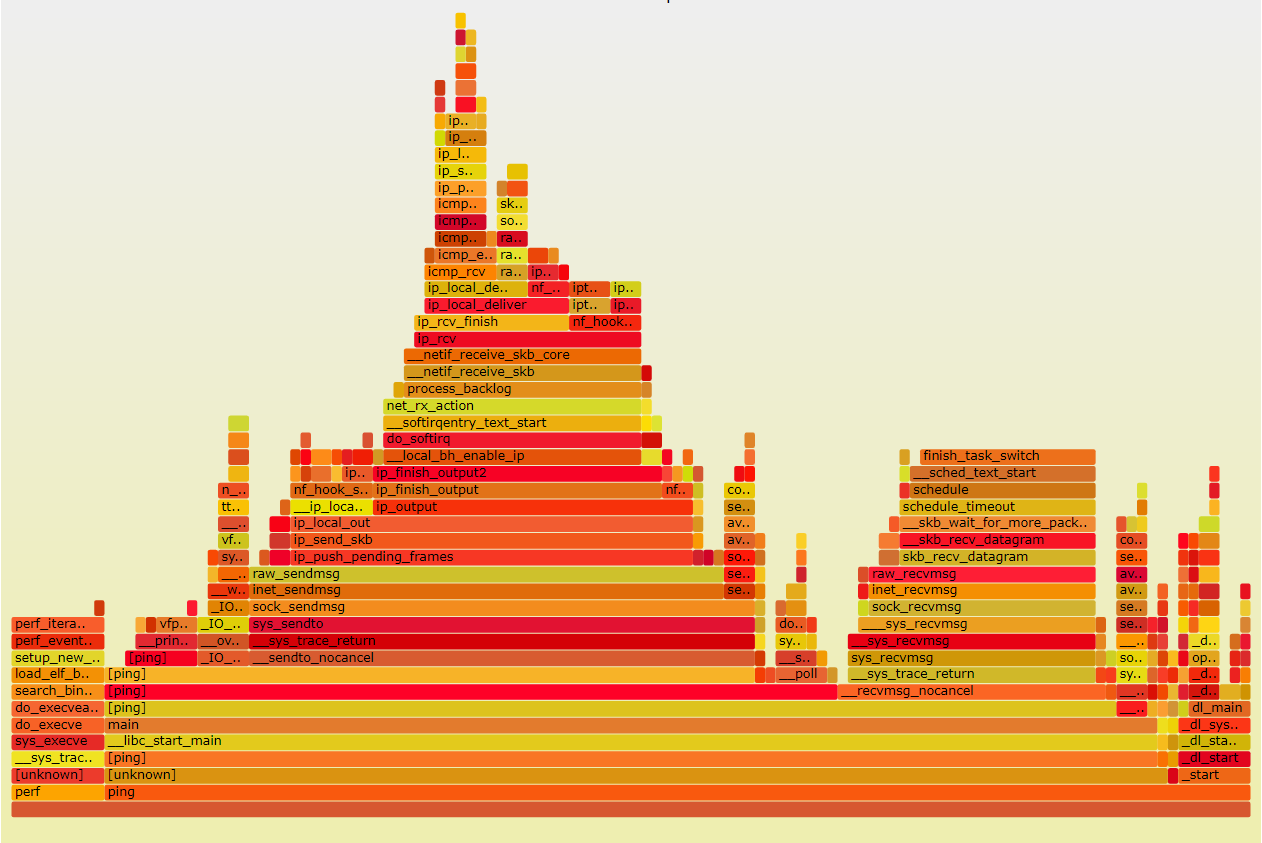
核心路径如下:
这里也是从系统调用sys_sendto开始, 但到了ip_finish_output2, 协议栈知道这是发给自己的报文, 于是直接放到下半部,快速的走icmp的接收流程, 并且最后通过loopback_xmit发送icmp相应报文.
这个发送的报文通过loopback这个"设备"驱动来收包, 走标准的linux收包流程.
流程如下:
3.3. ping localhost
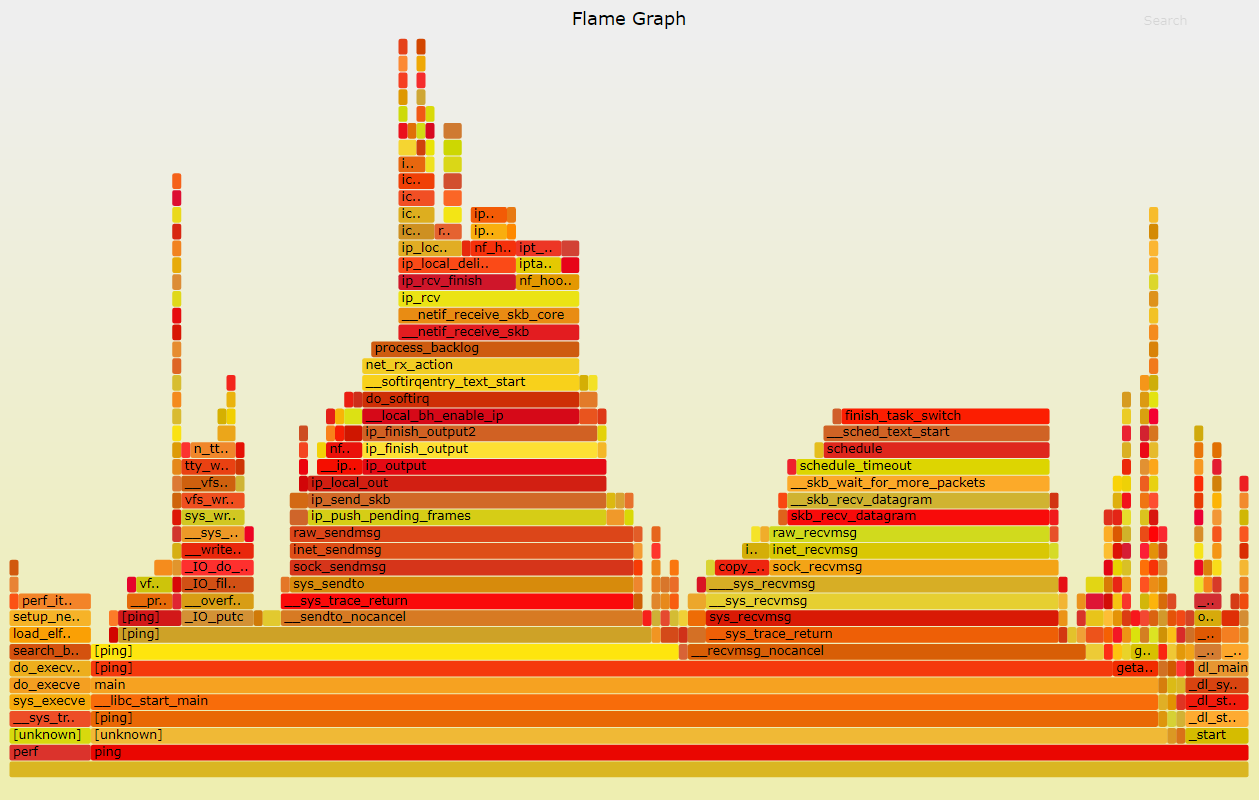
4. 结论
- 三种方式的接收路径基本相同, ping调用
sys_recvmsg接收报文, 导致内核在skb_recv_datagram路径上等待, 并主动让出CPU; 而从物理网口的driver接收报文很可能跑在其他CPU上(这个过程并不会被perf采样到, 因为我们是对进程号进行捕捉的), 收到并唤醒这里的等待, 进而接收报文路径返回. - ping peer通过物理网卡驱动发包(好像这是废话...)
- ping localhost和ping self的发送流程类似, ICMP请求报文并没有真正"发送", 在ip层就直接走下半部接收流程, 直到ICMP回应报文通过"localhost"设备发出.
4.1. latency
| ping | latency ms (avg) | delta | % |
|---|---|---|---|
| local | 0.077 | 0 | 100% |
| peer | 0.134 | 0.057 | 174% |
peer方式比local方式的latency多了0.057ms, 结合以上分析, peer方式多了4次物理网卡驱动收发(Host B物理发, Host A物理收, Host A物理发, Host B物理收), 所以多的时间(57 us)就是这部分相关的硬件和驱动的处理时间.